About Us
Our Story
The DataSquad is a team of undergraduate students who support data-related projects at UCLA. Our mission is to facilitate data processes for sustainable, replicable, and reproducible research, teaching, and workflows. Members of the DataSquad do not create, interpret, analyze, dictate, or otherwise change the nature of data sets outside of the prescribed task. The DataSquad is a part of the UCLA Library Data Science Center service and was made possible with a generous gift from Norman Powell. The UCLA DataSquad service is a chapter of the DataSquad International, a service model initiated by Carleton College.
Our Services
Our aim is to make your research and work life easier!
Coding Consultation
Do you need help with R, Python, Tableau, or other statistical programming tools? We can help you write efficient and cohesive code and recommend the best coding practices and tools for your project.
Data Cleaning and Manipulation
Do you need help with collecting, cleaning, and using data? Our team can help clean and manipulate your data in Python, R, and SQL.
Data Visualization
Need help with visualizing or displaying the data you have? Our members can help build informative and attractive visuals using Tableau, R’s ggplot, base R, and Python.
Statistical Consulting
Do you need help understanding statistical concepts or how to implement analysis using statistics in your projects? Our members have strong backgrounds in the subject of statistics.
Contact Us
Two ways to get help from the DataSquad team
Walk-in Hours
YRL Collaboration Pods, Room 11630L
No appointment needed
| Day | Hours |
|---|---|
| Monday | 1:00 p.m. – 6:00 p.m. |
| Tuesday | 10:00 a.m. – 11:30 a.m. |
| 12:30 p.m. – 2:00 p.m. | |
| 3:30 p.m. – 6:00 p.m. | |
| Wednesday | 10:00 a.m. – 6:00 p.m. |
| Thursday | 10:00 a.m. – 6:00 p.m. |
Schedule a Consultation
Book an in-person or online consultation with the DataSquad team.
Appointments available in-person at YRL or online via Zoom.
Projects
Ongoing and Past Projects DataSquad Has Worked On

Carceral Ecologies: LAPD Flight Data
R, Data Engineering

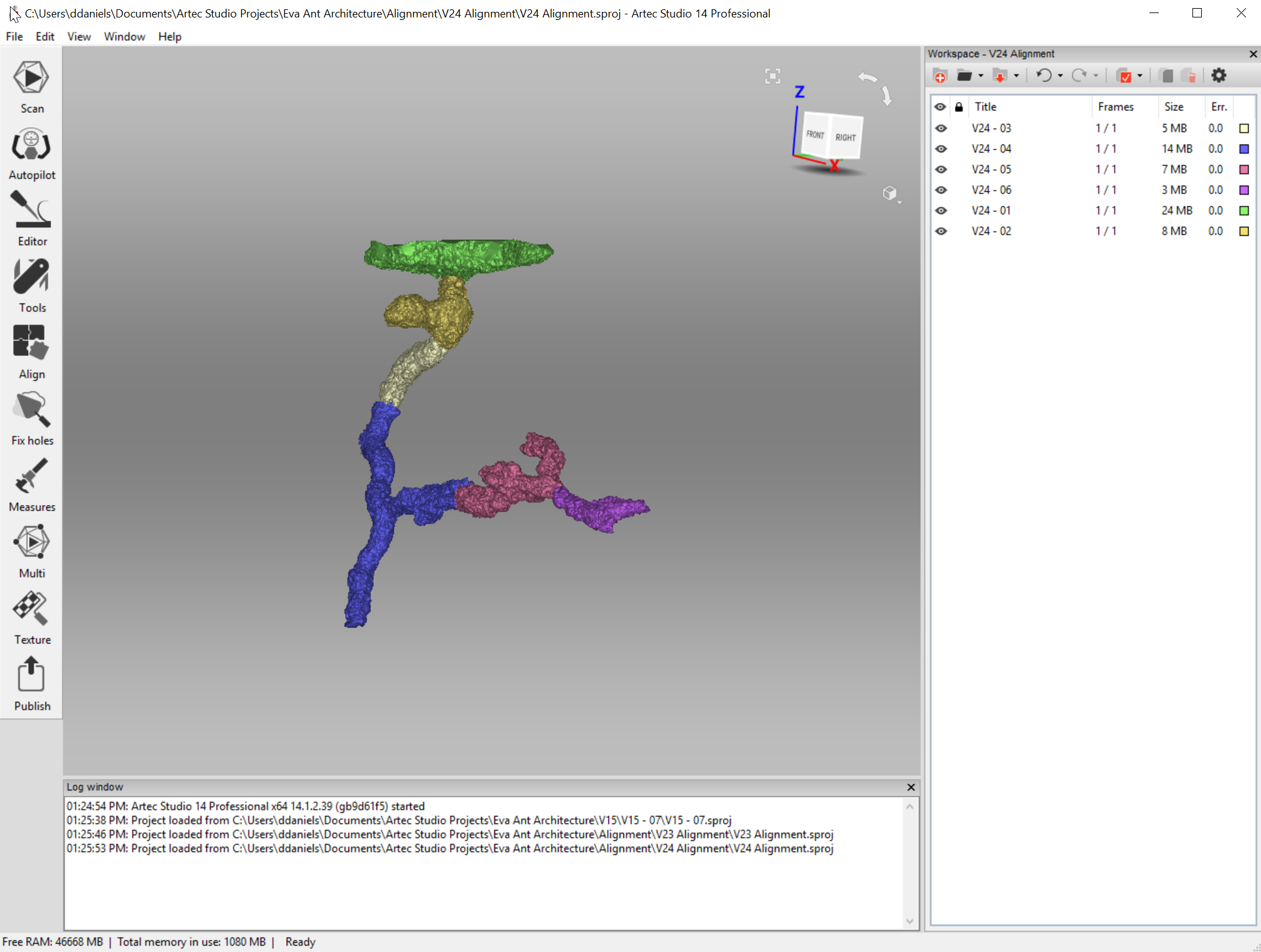
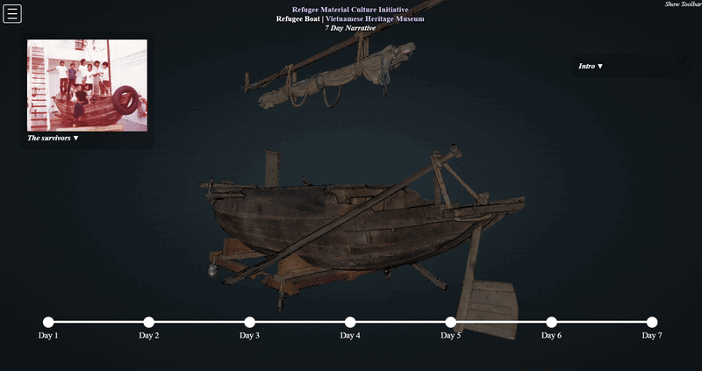
Refugee Heritage: 3D Digitization
3D Scanning, Digital Exhibits

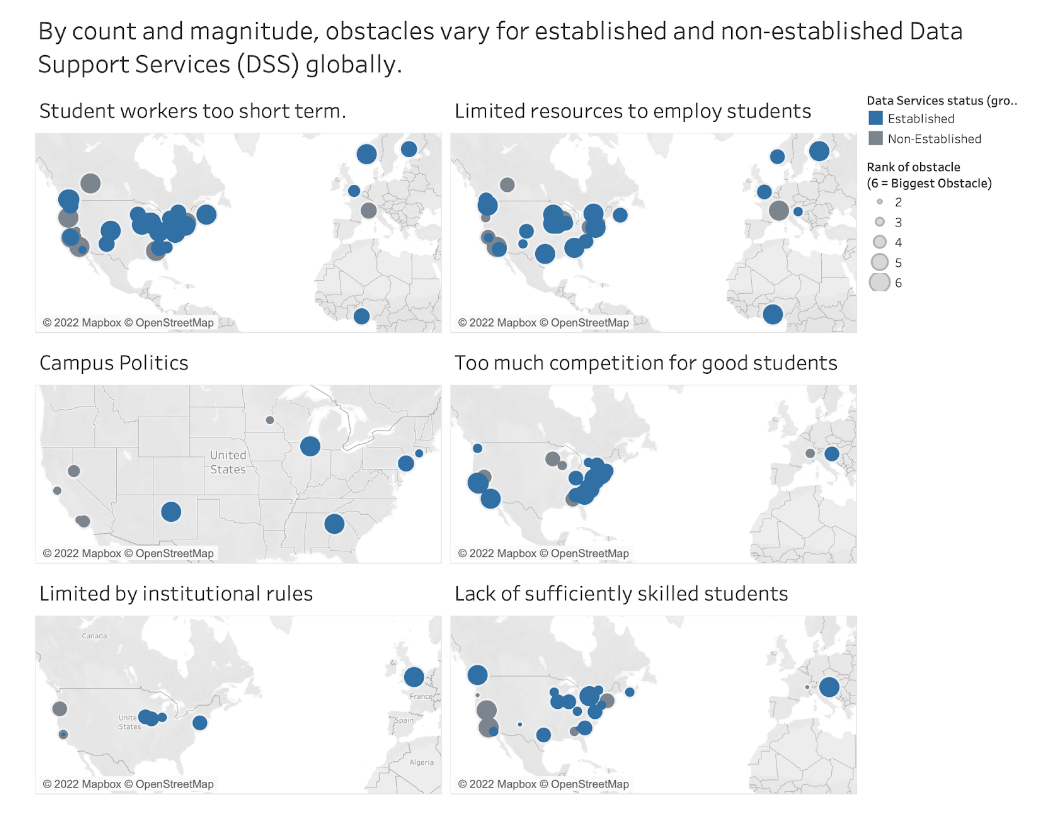
Shedding Light on Injustice
R, Python, OpenRefine, Tableau

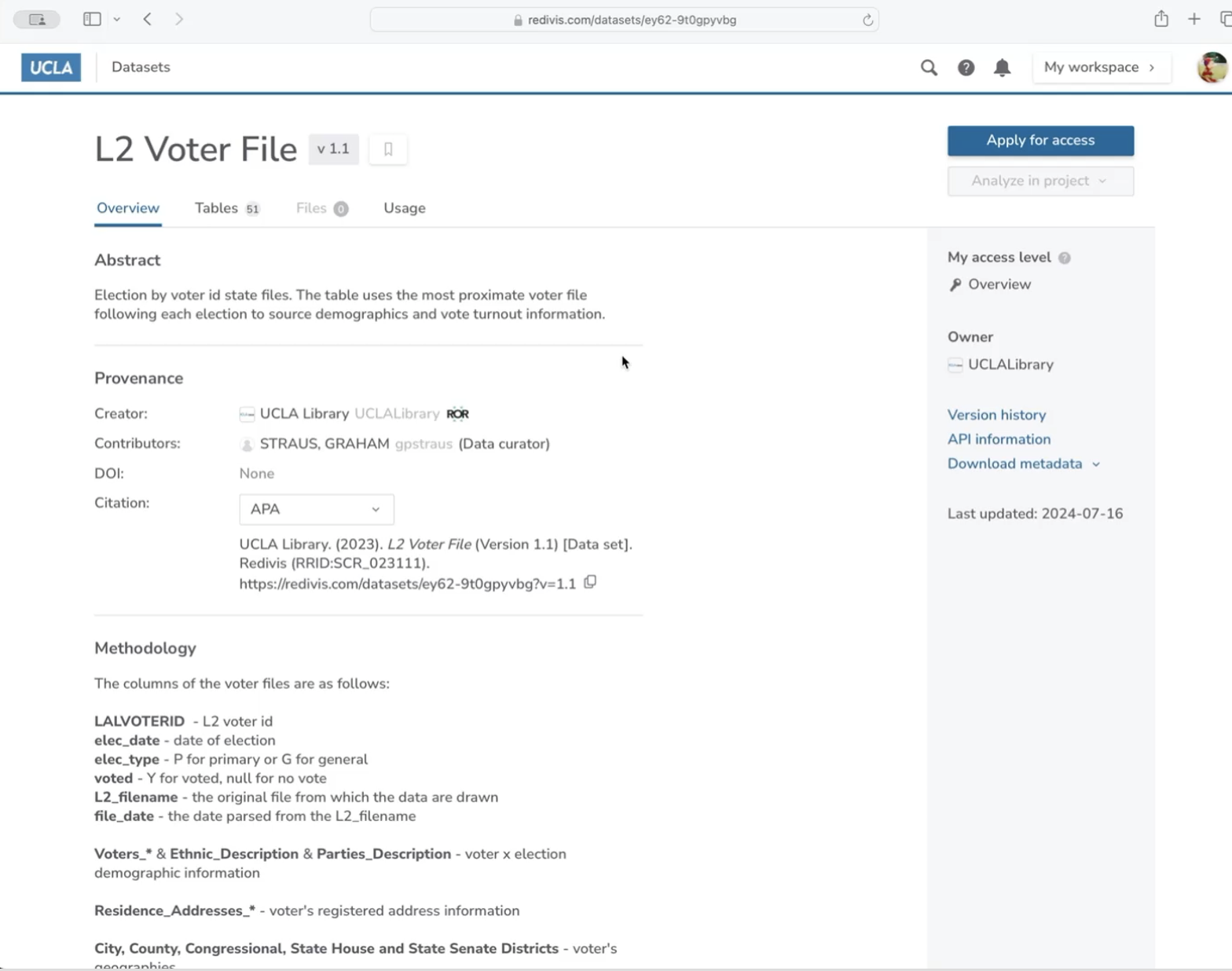
10TB Voter File: Making Data Research-Ready
Redivis, Data Engineering

Como-Q - Your Skincare Assistant
DataSquad International

The First UCLA DataSquad
Digitalizing Ant Nests to Study Tunneling Trends

Squirrels in Motion

Analyzing Ancient Chinese Buddhist Text with Python
Our Blog
These are blogs on what we've done
| Date | Title | Author |
|---|---|---|
| 01-30-2025 | Recent Projects at the DSC | Madeline Kim |
| 01-27-2025 | New DataSquad Member: Connor Lim | Madeline Kim |
| 11-17-2024 | Introducing the 2024-2025 DataSquad! | Madeline Kim |
| 03-14-2024 | Using Tools to Automate the Extraction of Metadata and Text for Research | Aimee Xu |
| 07-27-2023 | From African American 188 to Helicopter Surveillance: Kate McInerny’s symbiotic relations… | Emily Gong |
| 07-15-2023 | DataSquad Spotlight: Kristian Allen | Emily Gong |
| 05-27-2023 | DataSquad Spotlight: Tristan Dewing | Emily Gong |
| 06-02-2022 | The First UCLA DataSquad | William Foote |
| 09-16-2021 | Harmonizing Data to Under'stan'd Music Industry Success | Library Staff |
Team
UCLA DataSquad

Lian Elsa Linton
Project Manager

Connor Lim
Data Scientist

Shawn Wang
Data Scientist

Audrey Garcia
Data Scientist

Gianna Kim
Data Scientist
Staff

Tim Dennis
Program Co-director

Leigh Phan
Program Co-director

Kristian Allen
Software Architect

Doug Daniels
Emerging Technologies Librarian

Jina (Jamie) Jamison
Collection Manager
Hall of Fame
UCLA DataSquad Consultant Alumni

Lawrence Lee
Project Manager

Eric Huang
Data Scientist

Madeline Kim
Data Scientist

Loretta Hu
Data Scientist

Zhiyuan Yao
Program Co-director

Julia Wood
Data Science Consultant 2021-22

Keona Mae Pablo
Project Manager 2021-22

Wiliam Foote
Technical Writer 2021-22

Ethan Allavarpu
Data Science Consultant 2021-22

Vince Front
Project Manager 2022-23

Shail Mirpuri
Norman Powell Data Science Consultant 2022-23

Tristan Dewing
Norman Powell Data Science Consultant 2022-23

Emily Gong
Project Manager 2023-24

Hyerin Lee
Data Science Consultant 2023-24

Aimee Xu
Data Science Consultant 2023-24

Lukas Hager
Data Science Consultant 2023-24

Aditya Bharath
Data Science Consultant 2023-24

Bianca Badajos
Lux Lab Student Programmer 2023-24